

В данной статьей мы подготовили максимальной развернутое руководство по предназначению, созданию и настройке файла robots.txt для управления индексацией вашего сайта. Данный FAQ будет полезен собственникам сайтов, вебмастерам для своих проектов, а также SEO-специалистам, как начинающим (вникнуть и разобраться), так и опытным (освежить знания и все актуальные обновления).
Содержание статьи
- Что такое robots.txt и зачем он нужен
- Что такое поисковый робот и как он работает
- Из чего состоит файл robots.txt
- Требования к самому файлу robots.txt
4.1. Месторасположение файла robots.txt
- Директивы файла robots.txt
5.1 Директива User-agent
5.2 Директива Allow
5.3 Директива Disallow
5.4 Директива Host
5.5 Директива Sitemap
5.6 Директива Clean-param
5.7 Директива Crawl-Delay
- Как проверить robots.txt
- Файл robots.txt для популярных CMS
8.1. Создание файла robots в WordPress
8.2. Создание файла robots в Битрикс
8.3. Создание файла robots в Joomla
1. Что такое файл robots.txt и зачем он нужен
Файл robots.txt – это системный файл, который представляет собой текстовый документ (.txt) и соответствует стандарту исключений для роботов поисковых систем.
Для чего нужен файл роботс:
Роботс тхт включает одно или несколько правил, каждое из которых запрещает или разрешает тому или иному поисковому роботу доступ к определенному пути на сайте.
Как работает файл robots.txt:
Метод заключается в создание файла на сервере, который определяет правила доступа к данным сервера для роботов. Данное решение легко реализуемо на любом WWW-сервере, а сам робот получает набор правил доступа с помощью одного извлечения файла.
Это интересно знать:
- Стандарт robots.txt появился в 30 января 1994 году, был принят на консорциумоме W3C.
- Создал стандарт Мартин Костер, после того как роботы положили его сайт. Почему стандарт появился в общем: в 1993-1994 году поисковые роботы посещали сервера, где их совсем не ждали или это было ненужно (завал запросами роботов к серверу, обход непригодных частей сервера (глубокие виртуальные деревья, дублированная информация и т.д.)). Появилась необходимость в механизме, который позволял бы указать роботам части сервера, которые недоступны для сканирования.
- Почему выбрали именно именно текстовый документ и название файла “robots” (в переводе – роботы)? Расширение файла не должно требовать дополнительных настроек сервера. Имя файла должно быть легко запоминаемым и иметь низкую вероятность сходства с другими файлами.
- 1 июля 2019 Google объявил, что ведется работа над превращением протокола robots.txt в стандарт интернета.
- В 1996 году был предложен расширенный стандарт robots.txt, с директивами Request-rate и Visit-time.
2. Что такое поисковый робот и как он работает
Поисковый робот – это робот, который автоматически сканирует сайт путем рекурсивного доступа к известным URL-адресам (страницам, которые доступны через браузер). Если робот обнаружил новый URL-адрес через карту сайта или ссылку на сайте – робот также выполняет сканирование этого адреса.
У поисковиков есть разные поисковые роботы, каждый из которых имеет свое предназначение.
Какие задачи выполняют поисковые роботы:
- обработку запросов извлечение документов с сервера;
- проверку ссылок;
- проверку доступности сайта/сервера;
- мониторинг изменений и обновлений документов;
- анализ контента страниц для размещения контекстной рекламы (если сайт добавлен в систему контекстной рекламы).
Как поисковый робот ведет себя вашем на сайте:
- Запрашивает файл robots.txt. Это происходит при обращение к серверу (другими словами, представим, что робот приходит в ресторан и запрашивает меню). Важно отметить, что поисковый робот обращается к файлу роботс не при каждом обращение к серверу.
- Выборочно скачивает документы. Робот указывает конкретные типы данных, которые необходимы для обработки. Основные роботы поисковиков первоочередно делают запрос на текстовые документы (без учета стиля оформления CSS), изображения, видео, а также файлы в других расширениях PDF, Rich Text, MS Word, MS Excel и др.
Примечания:
- Предсказать путь поискового робота по сайту, как правило – невозможно;
- Робот делает запросы с определенным интервалом, чтобы не перегрузить сервер.
3. Из чего состоит файл robots.txt
Давайте разберемся, что должно быть в файле robots.txt. Текстовый документ роботс состоит из записей, которые разделяют одна или более пустых строк (с помощью символов CR, CR/LF или LF).
Запись – это непустая строка со структурой:
<field>:<value><#optional-comment>
Или:
<поле>:<пробел><значение><пробел>
Где <поле> — это наименование директивы, а <значение> — это конкретное значение указанной директивы. Пробелы не обязательны, при этом Google рекомендует использовать их для удобства чтения файла.
Мы разобрались с полями и значениями, давайте разберемся со структурой
Файл робот состоит из групп, каждая из которых может содержать разный набор правил (директив) в формате 1 правило – 1 строка.
Каждая группа состоит из:
- указания робота, для которого будут применены директивы;
- к каким каталогам и файлам у робота будет доступ;
- к каким каталогам и файлам у робота доступа не будет.
Примечания:
- Комментарии можно размещать в любом месте файла, обозначая их символом # в начале строки;
- Пробельные символы в начале и конце строки игнорируются;
- Регистр до двоеточия не учитывается, т.е. можно указать User-agent или USER-AGENT – это не имеет значения. А вот регистр после двоеточия учитывается, к примеру Url.html и url.html – будут разными адресами;
Для Яндекса. Недопустимо наличие пустых переводов строки между директивами User-agent, Disallow и Allow.
4. Требования к самому файлу robots.txt
Поисковые системы Google и Яндекс описывают четкие требования для файла robots.txt в своих инструкциях (инструкция Google, инструкция Яндекс).
Мы собрали общий набор требований, которые необходимо соблюдать для обоих поисковых систем:
- название файла или как правильно написать название файла: исключительно “robots”
- файл должен содержать текст в кодировке UTF-8 (включает коды символов ASCII), другие наборы символов запрещены;
- строки должны разделяться одной или несколькими пустыми строками;
- максимальный размер файла, установленный Google, составляет 500 КБ, тем не менее ограничение у Яндекса 32 КБ (если больше – робот считает доступ к содержимому сайту открытым);
- размещение файла – только корневая директория;
- использование кириллицы запрещено, используйте Punycode для указания адресов в кириллице (в кириллице допускается указание адреса сайта в директиве Sitemap (к примеру: вашсайт.ру/sitemap.xml));
- для каждого поддомена (субдомена) добавляется свой файл robots.txt.
4.1. Месторасположение файла robots.txt
Разберемся где должен находиться файл robots txt обязательно должен находиться в корневой директории вашего сайта.
Корневая директория – это место размещение всех файлов вашего сайта. Папка, в которой размещены файлы на хостинге или сервере может называться www или public_html.
Правильная ссылка на файл:
www.yousite.com/robots.txt
Т.е. если стоит вопрос как посмотреть роботс сайта, просто добавьте к адресу сайта /robots.txt
5. Директивы файла robots.txt
Мы уже разобрались в структуре файла роботс, месте его размещения, теперь давайте разберемся как правильно настроить файл robots.txt, а именно с основными директивами, которые необходимо знать для корректной настройки.
5.1 Директива User-agent
В директиве User-agent указывается робот, который должен следовать указанным ниже инструкциям ИЛИ * (звездочка), которая указывает, что указанные правила действуют для всех роботов.
User-agent: *
или укажем поискового робота Google:
User-agent: Googlebot
Примечания:
- Если есть конкретное указание робота поисковой системы, к примеру User-agent: Yandex, то строка User-agent: * не учитывается.
- Если обнаружены директивы для конкретного робота, директивы User-agent: Yandex и User-agent: * не используются.
Чтобы составить правильный файл robots.txt для Google и Яндекс, нужно знать основных поисковых роботов.
Основные поисковые роботы Яндекса:
- YandexBot — основной индексирующий робот;
- YandexDirect — скачивает информацию о контенте сайтов-партнеров Рекламной сети, чтобы уточнить их тематику для подбора релевантной рекламы, особым образом интерпретирует robots.txt;
- YaDirectFetcher — робот Яндекс.Директа, особым образом интерпретирует robots.txt;
- YandexImages — индексатор Яндекс.Картинок;
- YandexMarket— робот Яндекс.Маркета;
- YandexMedia — робот, индексирующий мультимедийные данные;
- YandexMetrika — робот Яндекс.Метрики;
- YandexNews — робот Яндекс.Новостей;
- YandexPagechecker — валидатор микроразметки.
Полный список поисковых роботов Яндекс.
Основные поисковые роботы Google:
- Googlebot – основной индексирующий робот;
- Googlebot-Video – робот, индексирующий видео
- Googlebot-News – робот индексирующий новости
- Googlebot-Image – робот индексирующий картинки
Полный список поисковых роботов Google.
Рекомендации:
- Если вам нужно указать общие инструкции для всех роботов, используйте * (звездочку)
- Если вам нужно указать инструкции для каждого робота отдельно, используйте несколько User-agent, пример:
User-agent: yandex
Disallow: /category-2
User-agent: Googlebot
Disallow: /category-2
User-agent: Googlebot-Image
Disallow: /uploads
5.2 Директива Allow
Директива allow в robots.txt определяет разделы или страницы сайта, которые должны быть доступны указанным поисковым роботам для индексации.
Пример использования директивы Allow:
User-agent: Googlebot-Image
Аllow: /images
Disallow: /
# комментарий: запрещаем индексировать ВЕСЬ сайт, но
# позволяет индексировать все страницы, которые начинаются
# с /images для робота Googlebot-Image
Рассмотрим пример совместного использования директивы Allow и Disallow:
User-agent: *
Аllow: /about-us.html
Allow: /catalog/*.html$
Disallow: /
# запрет индексации всех страниц кроме /about-us.html, а также все файлы .html, которые идут через путь /catalog/
Важные примечания из справки Яндекс:
- При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow.
- Директивы сортируются по длине URL от самого короткого до самого длинного, применение директив происходит последовательно.
- Порядок следования директив в файле robots.txt не влияет на использование их роботом;
- Если раздел или страница не указана, она игнорируется:
Allow:
Рассмотрим пример сортировки строк по длине (т.е. какой будет порядок обработки), стандартный вариант:
User-agent: yandex
Disallow: /category
Disallow: /category-2
Disallow: /img
Disallow: /admin
Который будет обработан в следующей последовательности:
User-agent: yandex
Disallow: /img
Disallow: /admin
Disallow: /category
Disallow: /category-2
5.3 Директива Disallow
Что значит директива Disallow в robots.txt
Директива Disallow используется для закрытия от индексации нужных каталогов, файлов или страниц сайта. По умолчанию, если доступ не закрыт с помощью Disallow – робот может обрабатывать такие страницы.
Начинаем разбираться как запретить индексацию robots.txt. Начать стоит с того, для каких страниц или разделов сайта необходимо использовать данную директиву:
- страницы с параметрами (для Яндекса);
- страницы результатов поиска;
- страницы с персональной информацией пользователей;
- системные страницы: авторизация, регистрация, формы.
Давайте разберем примеры использования директивы Disallow:
Важно: значения директивы чувствительны к регистру!
Как закрыть сайт от индексирования всеми поисковыми системами целиком:
User-agent: *
Disallow: /
Как закрыть от индексации весь сайт кроме главной страницы сайта (полностью сайт от индексации):
User-agent: *
Allow: /$
Disallow: /
Как запретить индексацию определенной страницы:
User-agent: *
Disallow: /catalog/razdel.html
Как закрыть раздел от индексации (а также всего его содержимого):
User-agent: *
Disallow: /catalog/razdel/
ИЛИ:
User-agent: *
Disallow: /catalog/razdel$
Как запретить индексацию всех страниц, которые начинаются с определенного раздела:
User-agent: *
Disallow: /catalog/razdel
#без слеша в конце, запрещает /catalog/razdel, а также /catalog/razdel.html
Как запретить индексацию параметров страницы:
Используем ? после значения в директиве Disallow
User-agent: *
Disallow: /catalog/razdel?
ИЛИ:
User-agent: *
Disallow: /add.php?*user=
# Запрещает все скрипты 'add.php?' с параметром 'user'
Давайте разберемся со спецсимволами в robots.txt:
- * обозначает 0 или более экземпляров любого действительного символа;
- $ обозначает конец URL.
Как запретить индексацию всех страниц с определенным расширением (например .html), по определенному пути:
Используем * перед значением в директиве Disallow.
User-agent: *
Disallow: /catalog/*.php*
# запрещает все страницы с .php по любому пути, который начинается с /catalog/
Как запретить индексацию всех одинаковых каталогов по одному пути:
User-agent: *
Disallow: /catalog/*razdel
# запрещает раздел /catalog/razdel, а также /catalog/category/razdel
Используем ? после значения в директиве Disallow.
Зачем? По умолчанию в конце каждой директивы и ее значения приписывается спецсимвол *.
User-agent: *
Disallow: /catalog*
# тоже самое, что и Disallow: /catalog
Спецсимвол $ используется для отмены правила *, например:
User-agent: *
Disallow: /page$
# запрещает /catalog, но не запрещает /page.html
При этом, спецсимвол $ не запрещает указанный * на конце:
User-agent: *
Disallow: /page$ # запретит только /page
Disallow: /page*$ # аналогичен Disallow: /page,
# и запрещает /page и /page.html
Как запретить индексацию конкретного файла:
User-agent: *
Disallow: /catalog/razdel/file.xls
Как запретить индексацию всех файлов определенного типа (например .xls):
User-agent: *
Disallow: /*.xls$
Как запретить индексацию всем разделам, которые содержат по пути определенную категорию
User-agent: *
Disallow: /*/category-1/
# Запрещает все урлы, которые содержат /category-1/
Частые ошибки использования директивы Disallow:
Пример 1. Ошибка комбинации 2 директив:
User-agent: *
Allow: /
Disallow: /
# все разрешено!
Пример 2. Ошибка комбинации 2 агентов (директива означает: для всех роботов закрыт для индексации, для яндекса – открыт):
User-agent: *
Disallow: /
User-agent: Yandex
Allow: /
Пример 3. Если в директиве Disallow нет значения, то робот учитывает данные как в директиве Allow:/, пример:
User-agent: *
Disallow:
Если сайт не в индексе поисковой системы и стоит вопрос как вернуть сайт в индекс Google и Яндекс – для начала проверьте директивы Disallow.
5.4 Директива Host
Директива Host – директива, с помощью которой задается главное зеркало сайта. Как правило указывается в конце списка директив в файле robots.txt
Host: yousite.com
Важно:
- 12 марта 2018 года Яндекс отказался от использования директивы Host, на замену пришел 301 редирект;
- Google не поддерживает директиву Host.
Поэтому, директива HOST для Google и Яндекс не актуальна и на сегодня ее использовать не нужно.
5.5 Директива Sitemap
Sitemap.xml – карта сайта (список всех страниц для индексирования).
Чтобы указать роботу ссылку на карту сайта, необходимо добавить в файл роботс. Если вы добавили карту сайта в консоль Google и Яндекс Вебмастер – это не обязательно. Тем не менее, мы рекомендуем добавлять ссылку на карту сайта в файл robots.txt.
Правильное указание ссылки на карту сайта:
sitemap: yousite.com/sitemap.xml
Если у вас несколько карт, которые не объединены одной общей картой – укажите все:
sitemap: yousite.com/sitemap-1.xml
sitemap: yousite.com/sitemap-2.xml
Примечание:
- Директива sitemap является межсекционной, поэтому она будет использоваться роботом вне зависимости от строки ее размещения в файле роботс
Стоит ли добавить sitemap в robots.tx? Это не обязательно, если карта сайта добавлена через вебмастера, тем не менее это рекомендуется сделать.
Рекомендации Яндекса по указанию ссылки на sitemap.xml в файле robots.txt:
https://yandex.ru/support/webmaster/robot-workings/sitemap.html
Рекомендации Google по указанию ссылки на sitemap.xml в файле robots.txt:
https://developers.google.com/search/reference/robots_txt?hl=ru
5.6 Директива Clean-param
Директива применяется только для Яндекса, Google не поддерживает Clean-param. Используется если URL страниц сайта содержат GET-параметры, например:
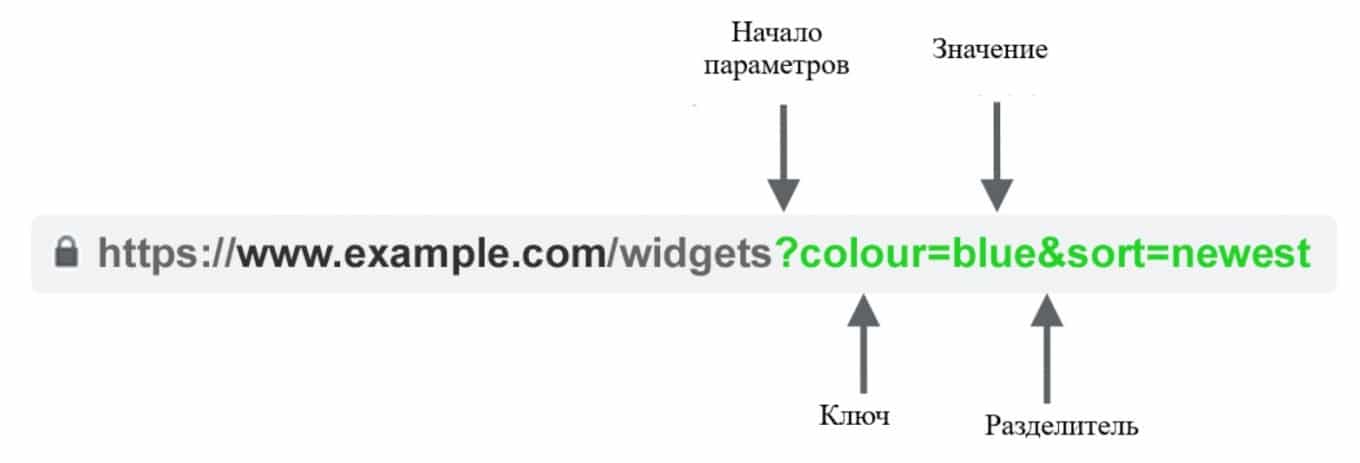
И вы хотите ограничить доступ робота к таким страницам. Таким образом робот Яндекса не будет многократно перезагружать дубли информации.
Что такое GET-параметры?
GET-запрос — это метод передачи данных от клиента к серверу. Цель – получение информации, которая указана с помощью GET-параметров. Эта параметры являются публичными данными, их можно посмотреть повторно, задав тот же URL адрес. GET-параметры можно использовать в том случае, когда информация является статичной и не меняется.
Из чего состоят GET-параметры:
- из домена;
- адреса страницы;
- самих параметров, после знака “?”.
Формат:
http://yousite.com/page.php?"ключ=объяснение"&"ключ=объяснение"
Давайте вернемся к первому примеру:
http://yousite.com/page.php?name=Иванов
Предположим, что таких страниц может быть несколько тысяч, теперь, если мы укажем директиву Clean-param в роботсе следующим образом:
User-agent: yandex
Disallow:
Clean-param: name /page.php
Робот Яндекса сведет все страницы такого типа к одной:
http://yousite.com/page.php
Это правило будет действовать для всех страниц, которые начинаются с /page.php
При этом, если параметр указывается в нескольких урлах, например:
http://yousite.com/page.php?name=Иванов
http://yousite.com/page-2.php?name=Иванов
Указываем в роботсе:
User-agent: yandex
Disallow:
Clean-param: name /page.php
Clean-param: name /page-2.php
Если параметров несколько, наприме:
http://yousite.com/page.php?name=Иванов&surname=Иванов
Указываем в роботсе:
User-agent: yandex
Disallow:
Clean-param: name&surname /page.php
Настройка параметров в Google:
В Гугл есть готовый инструмент «Параметры URL» в старой версии Google Search Console.
Какие проблемы для SEO создают параметры в URL-адресах:
- дублирование информации;
- расход краулингового бюджета;
- снижают кликабельность урлов.
Как решить проблемы с дублированием:
- удаление параметров;
- изменение динамических страниц параметров на статические;
- устранение дублей путем установки rel=”canonical” на страницы с параметрами;
- Директива noindex в мета-теге robots;
- Директива Disallow в файле robots.txt.
Примечания:
- Директива Clean-Param является межсекционной, ее можно указать в любом месте файла;
- В префиксе можно использовать символы только A-Za-z0-9.-/*_;
- Регистр учитывается;
- Длина правила максимум 500 символов;
- Если директив указано несколько, все они будут учтены роботом.
5.7 Директива Crawl-Delay
Если сервер не успевает обрабатывать запросы роботов – можно воспользоваться директивой Crawl-Delay.
Пример указания директивы Crawl-Delay в файле роботс:
User-agent: yandex
Crawl-Deley: 1.0 # задает тайм-аут в 1 секунду
Какие функции выполняет данная директива?
Директива Crawl-Delay задает минимальный период времени между загрузкой страниц в секундах, таким образом сервер будет успевать “отдышаться”.
Как правило, о сложностях сервера вы можете узнать 3-мя базовыми способами:
- сайт периодически перестает работать;
- с помощью вебмастера Яндекс и консоли Google;
- вопрос о недостаточности ресурсов сервера поднимет ваш хостер или системный администратор вашего сервера.
Перед тем, как задавать ограничения для робота в файле robots.txt, необходимо провести проверку страниц, к которым чаще всего обращаются роботы:
- Проанализируйте логи сервера;
- Проанализируйте какие страницы посещает робот в Яндекс.Вебмастере (Посмотрите список URL на странице Индексирование → Статистика обхода в Яндекс.Вебмастере (установите переключатель в положение Все страницы), а также в консоли Google.
Таким образом вы сможете определить, обращается ли робот к системным/служебным файлам сайта, к которым не должен. Если вы обнаружите их – закройте их через директиву Disallow.
– Директива Crawl-Delay для Яндекс
Поисковая система Яндекс – поддерживает директиву Crawl-Delay, кроме робота который обходит RSS-канал для формирования турбо-страниц.
Рекомендации и информация Яндекса:
- Если в файле robots.txt содержатся директивы Disallow и Allow, директиву Crawl-Delay необходимо добавить после них
- Поисковый робот Яндекса поддерживает дробные значения Crawl-delay (0.1, 0.2), при этом максимальная скорость, которую можно задать в директиве равна 0.2
Как задать скорость обхода в Яндекс.Вебмастере:
Перейдите в Индексирование → Скорость обхода:
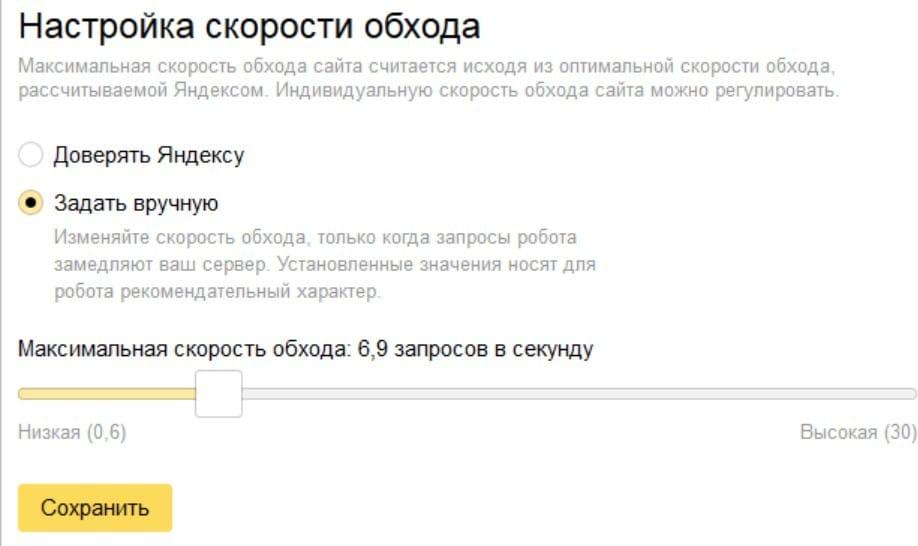
Инструкция Яндекс: https://yandex.ru/support/webmaster/robot-workings/crawl-delay.html
– Директива Crawl-Delay для Google
Поисковая система Google – НЕ поддерживает директиву Crawl-Delay. Скорость обхода сайта можно задать в Google вебмастере:
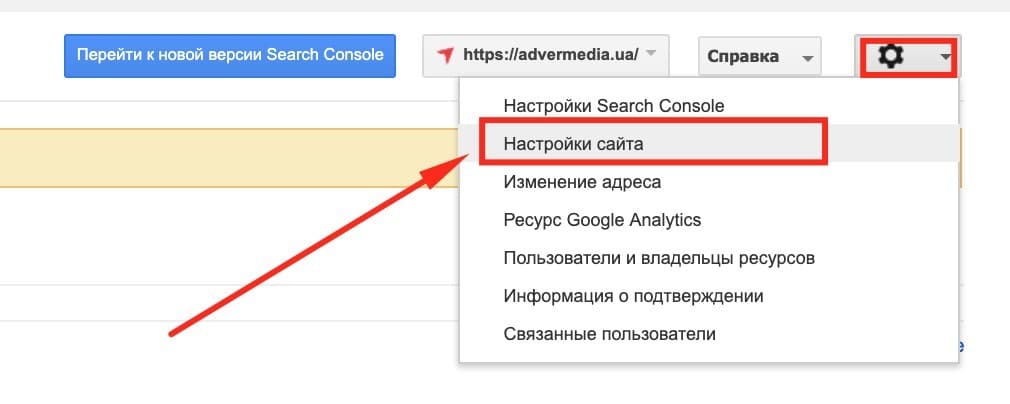
Далее:

Инструкция Google: https://support.google.com/webmasters/answer/48620?hl=ru
6. Как составить файл robots.txt
Есть 2 основных способа составления файла роботс:
6.1. Создаем файл робот вручную
Самый простой способ – создать файл робот тхт вручную. Создаем текстовый файл TXT, это можно сделать через текстовый редактор или Notepad, TextEdit.
Порядок действий:
- Создайте текстовый файл с названием robots.txt;
- Заполните файл;
- Сохраните;
- Получаем на выходе:

- После этого вам необходимо зайти на FTP сайта, проще всего это сделать через бесплатную программу FileZilla;
- Перейдите в папку public_html или www;
- Загрузить файл;
- Открыть его и проверить, что он доступен.
Также загрузить файл robots txt для WordPress можно через файловый менеджер на хостинге или через плагин WP файловый менеджер.
6.2. С помощью онлайн генератора
Файл robots txt онлайн можно создать с помощью генератора. В интернете достаточно много сервисов, позволяющие это сделать – десятки.
Мы собрали 5 наиболее удобных и полных генераторов файла robots txt для Google, Яндекс и других поисковых роботов. Все приведенные генераторы являются БЕСПЛАТНЫМИ.
Сервис 1. Генератор robots txt онлайн от PR-CY
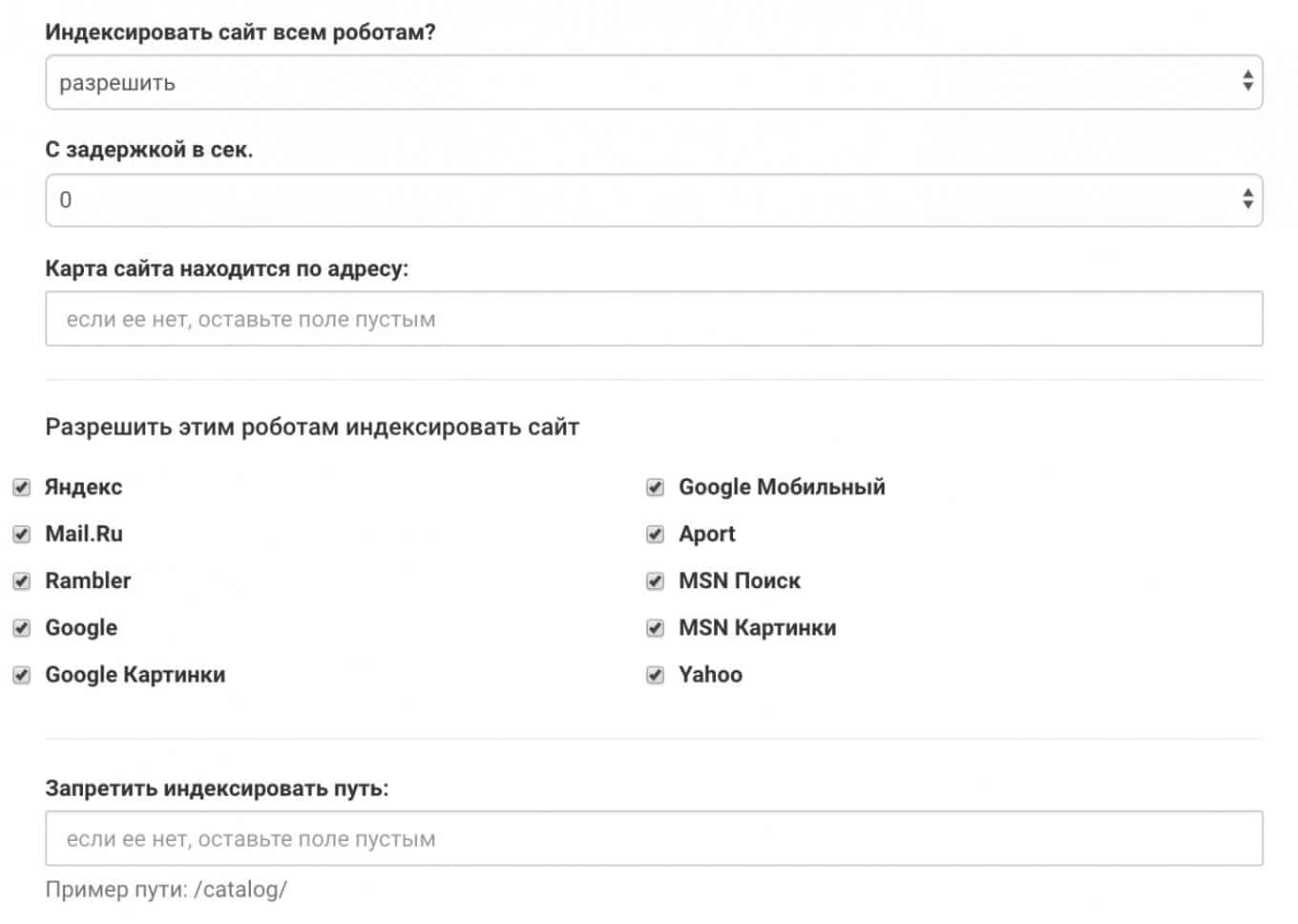
Сервис 2. Генератор robots txt онлайн от Seolib
Сервис 3. Генератор robots txt онлайн от Smallseotools

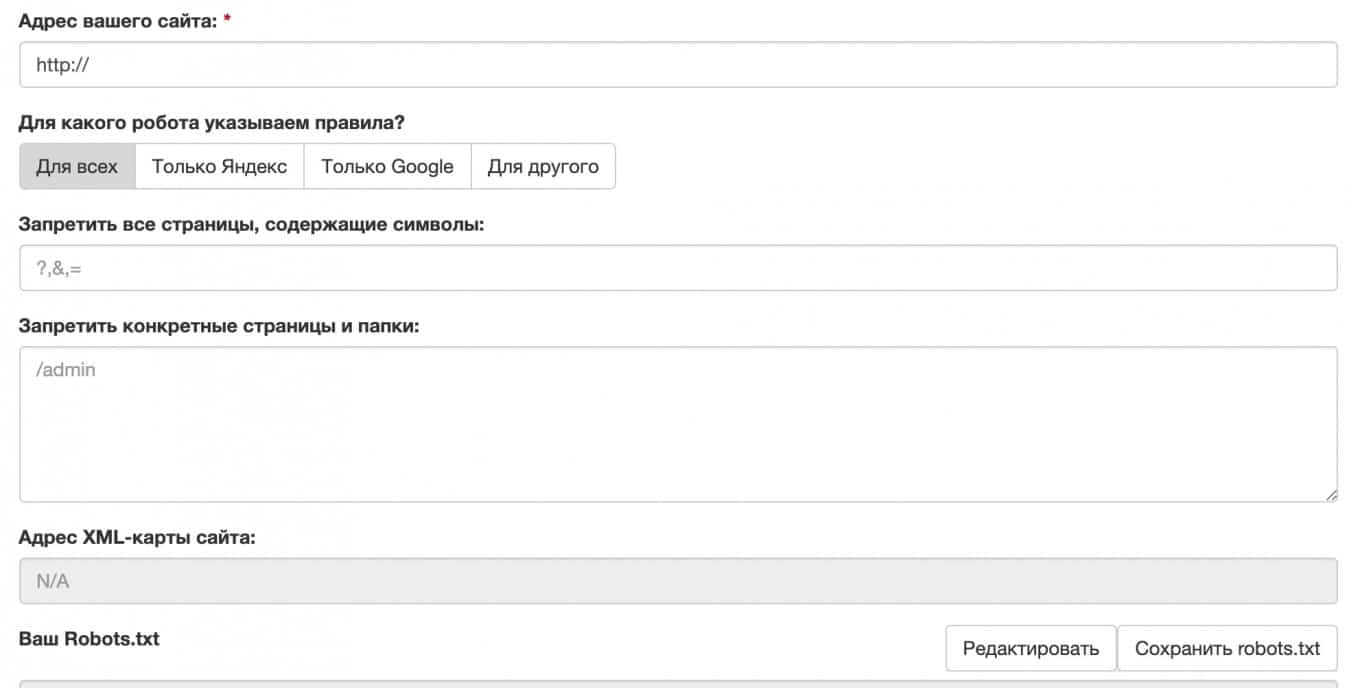
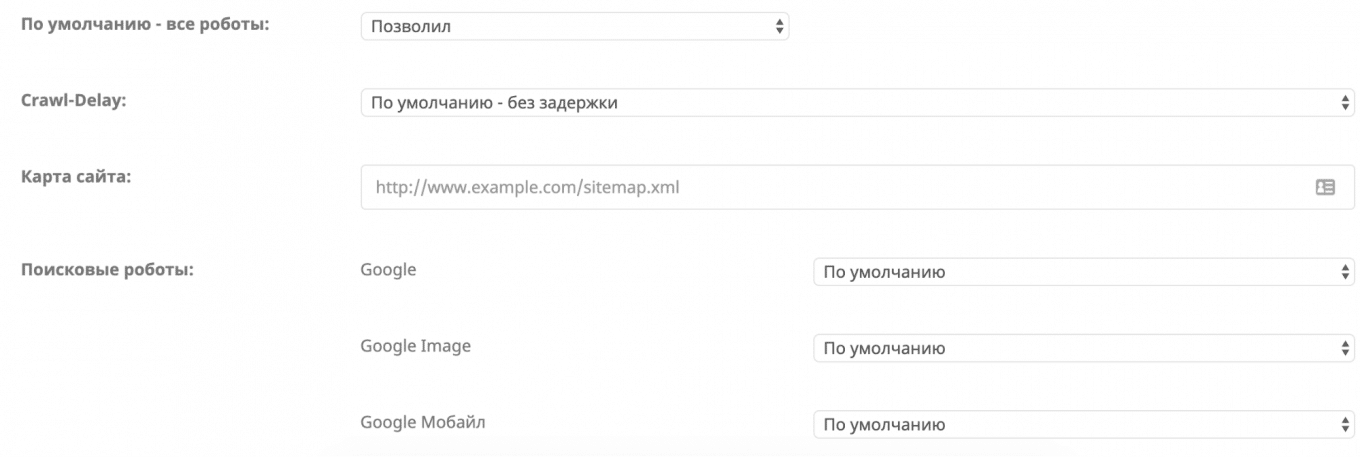
Сервис 4. Генератор robots txt онлайн от Seoptimer
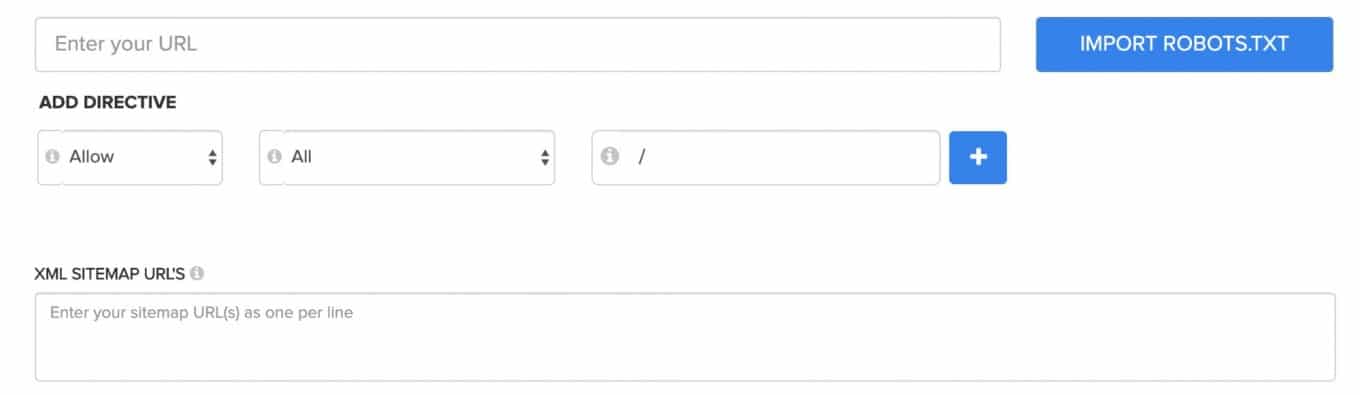
Сервис 5. Генератор robots txt онлайн от Lxrmarketplace
7. Как проверить robots.txt
– С помощью инструмента Google Robots Testing Tool
Итак, проводим анализ роботс тхт. Необходимо зайти в Google Search Console (вы должны быть авторизованы в своем аккаунте, а также вам сайт должен быть подтвержден), если ваш сайт не добавлен в вебмастер Google, воспользуйтесь инструкцией: Добавление сайта в поисковые системы: пошаговая инструкция
Пошаговая инструкция:
- Зайдите в вебмастер
- Перейдите по ссылке в старую версию вебмастера
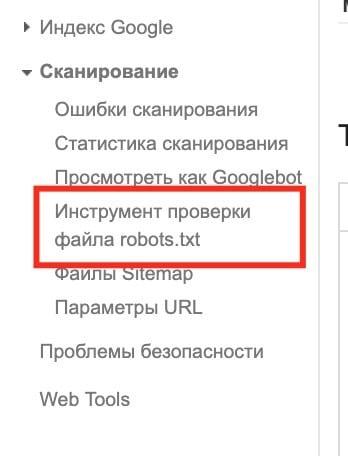
- Перейдите в раздел Сканирование – Инструмент проверки файла robots.txt
- Тут выполняется проверка робот, вы сможете увидеть данные по наличию ошибок:
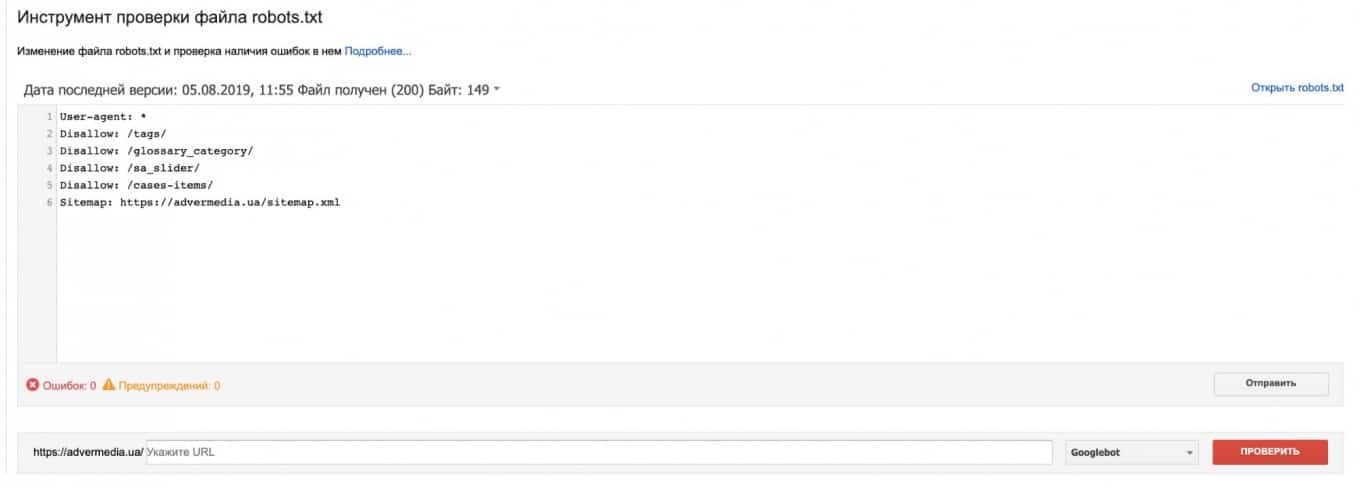
Инструкция Google: https://support.google.com/webmasters/answer/6062598
– С помощью инструмента Яндекс анализ robots.txt
В Яндекс Вебмастер проверка robots.txt выполняется с помощью специальной формы, в которой можно ввести адрес сайта и получить результат проверки.
Как это работает:
При проверке файла роботс через Яндекс.Вебмастер все достаточно просто:
- Перейдите по ссылке на анализатор Яндекса:

- Введите адрес своего сайта
- Получите результаты
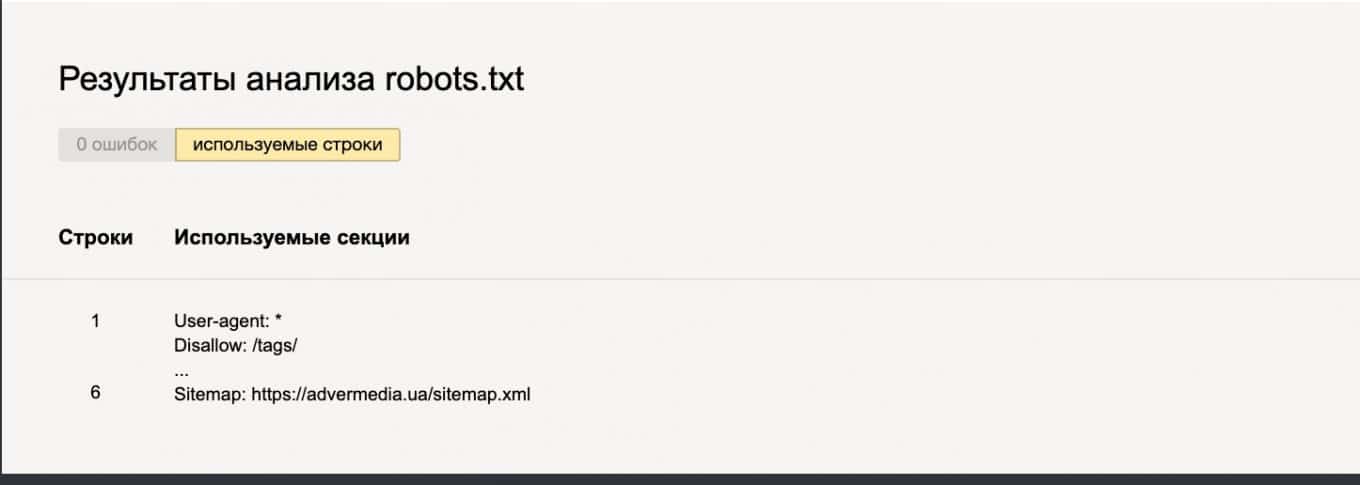
Помимо этого, Яндекс дает возможность проверки списка конкретных страниц, закрыты ли они от индексации:

8. Файл robots.txt для популярных CMS
Рассмотрим процесс создания файла роботс для 3 популярных систем управления, в каждой из которых есть свои, пусть и небольшие особенности.
8.1. Создание файла robots в WordPress
Создаем robots в СMS Вордпресс, для этого сначала нужно разобраться в особенностях самой системы управления в плане управления данным файлом.
Где находиться файл robots.txt в WordPress
Файл робот в CMS Вордпресс создается автоматически и располагается в корневом каталоге на вашем сервере.
К примеру, адрес вашего сайта: mysitewp.com.ua
Файл будет доступен по ссылке: mysitewp.com.ua/robots.txt
Что содержит стандартный файл robots.txt в WordPress:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Базовый файл robots WordPress содержит следующие правила:
User-agent: – определяет поисковых роботов, для которых будут действовать указанные в файле правила, где * (звездочка) означает – все поисковые боты, то есть это правило будет действовать для всех поисковиков.
Disallow: – запрет индексирования
В которых указаны каталоги/папки на сайте wp-admin и wp-includes, что говорит о том, владелец сайта запрещает индексировать поисковым роботам данные системные каталоги.
Данный стандартный файл роботс тхт – это виртуальный файл, то есть вы не найдете его в корневом каталоге сайта.
Если вам необходимо добавить свой файл robots txt для WordPress – просто загрузите новый файл в корневую директорию сайта (часто она называеться public_html или www).
Что обязательно нужно закрывать через robots.txt в WordPress
Ничего. Старайтесь использовать мета-теги для запрета от индексации.
Тем не менее, если говорить о классическом виде файла robots – двух правил стандартного файла, в большинстве случаев работы с сайтом – недостаточно, минимально необходимо добавить 2 дополнительных правила, а также ссылку на карту сайта:
User-agent: *
Allow: /wp-content/uploads/
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Sitemap: https://yousite.com/sitemap.xml
Где мы добавили:
Аllow: – разрешает для индексирования раздел с файлами и картинками
Disallow: для /wp-content/plugins/, что запрещает индексацию системных файлов плагинов
А также Sitemap: ссылка на карту сайта для поисковиков (это не обязательно, при добавление карты сайта в консоль вебмастера Google, а также вебмастер Яндекса).
Естественно, ваш файл robots txt для wordpress может выглядеть иначе, необходимо исходить из индивидуальных потребностей сайта, к примеру, если ваш сайт на этапе разработке и стоит вопрос как закрыть сайт от индексации WordPress:
User-agent: *
Disallow: /
Как быстро создать файл robots txt для WordPress
Итак, перед вами задача – настройка robots.txt в WordPress. Разберем 2 простых способа создания файла.
Способ 1. Создаем файл robots txt для WordPress вручную
Не останавливаемся на данном способе, он расписан выше в статье.
Способ 2. Создаем файл robots txt для WordPress с помощью SEO плагинов
Если стоит вопрос как изменить robots txt в WordPress – 2 наиболее популярных плагина, которые решают этот вопрос:
Плагин Yoast SEO
Переходим в редактор:

И сразу попадаем в область редактирования файла robots:
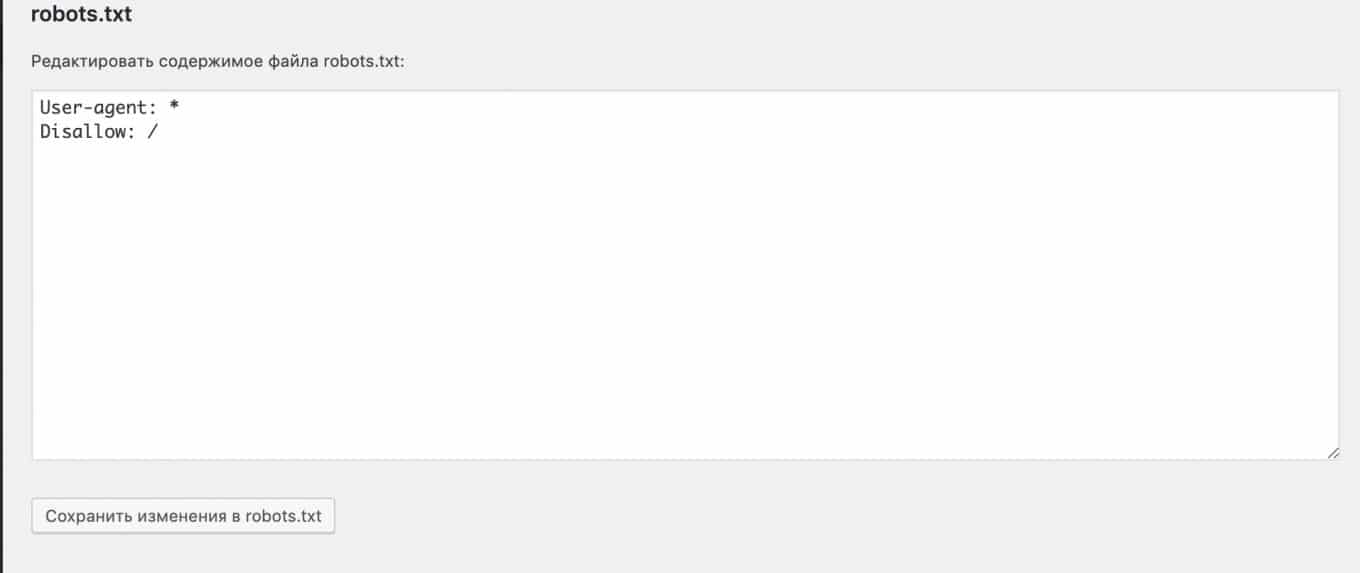
С помощью этого плагина выполняется удобная настройка индексации WordPress.
Плагин All in One SEO Pack
Необходимо перейти:

Активировать модуль:
Перейти в раздел:
Теперь вы можете настроить файл роботс вордпресс

8.2. Создание файла robots в Битрикс
Перейдите в Сервисы – Поисковая оптимизация – Настройка robots.txt
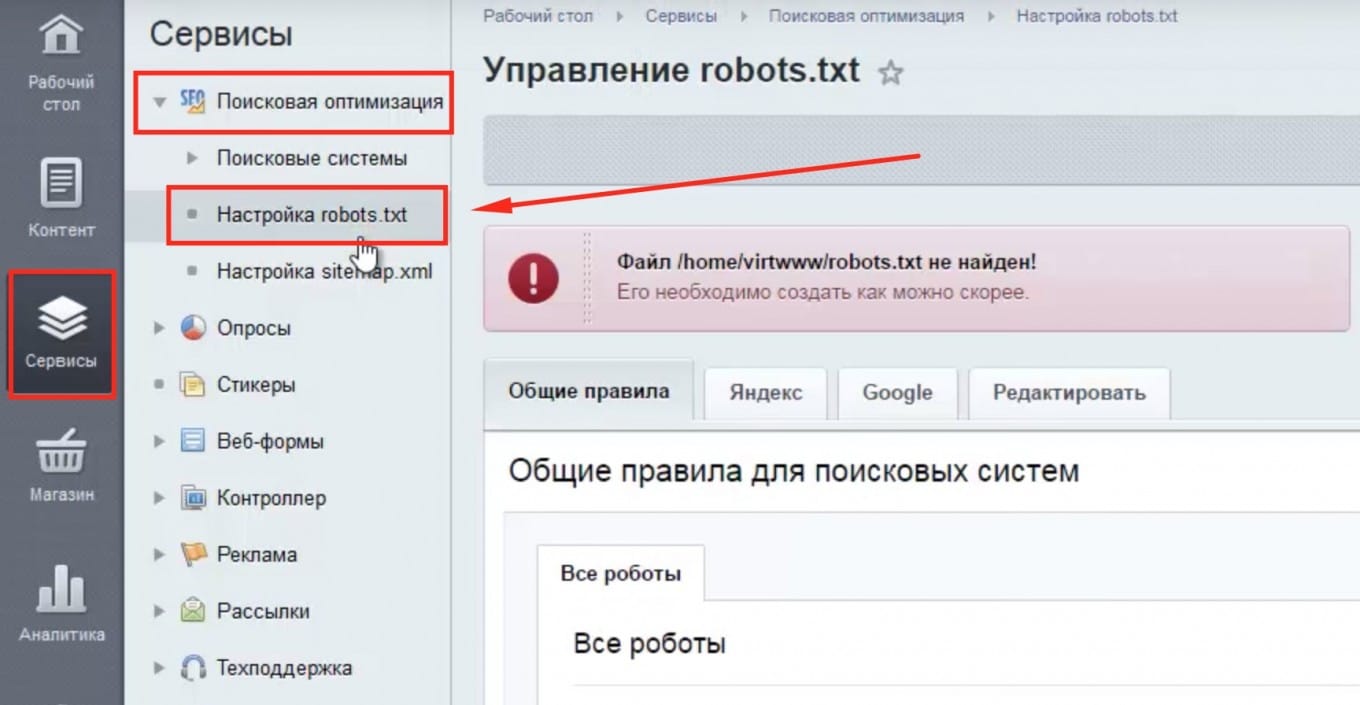
Далее необходимо выбрать Общие правила для всех роботов или Яндекс, Гугл
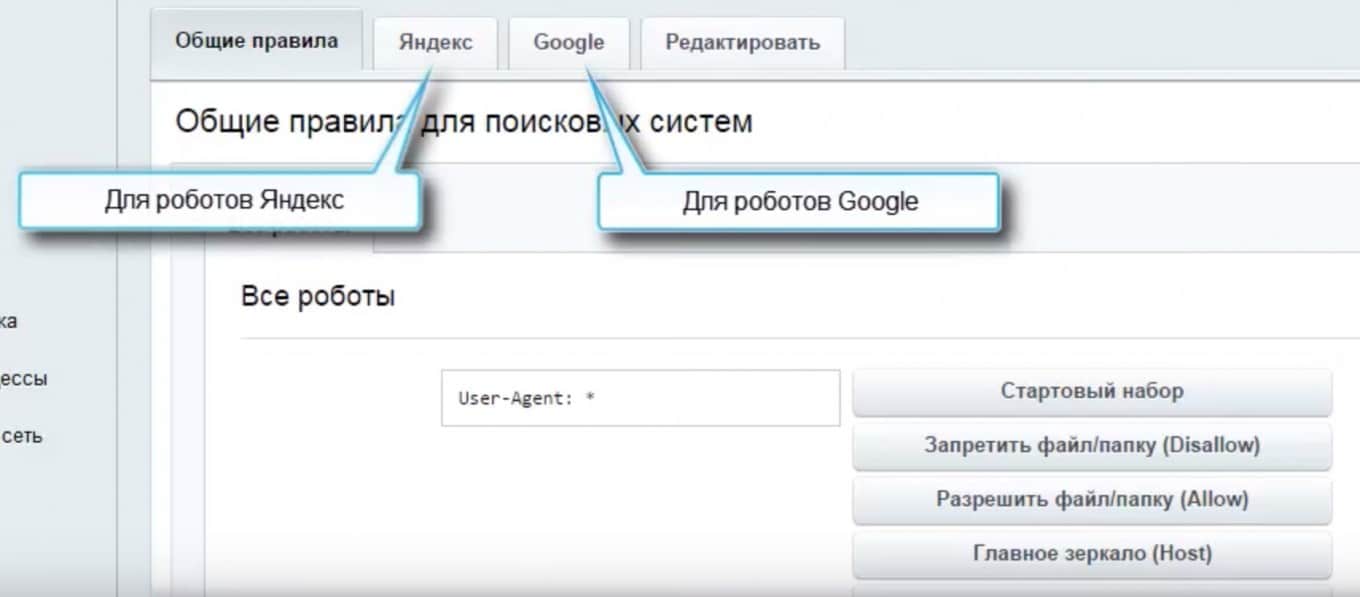
Нажмите на кнопку Стартовый набор справа, после чего нужно будет ввести адрес главного зеркала сайта.
Далее Битрикс сам предложит стартовый директив:

По ссылкам справа вы можете выбирать папки для открытия и закрытия от индексации:
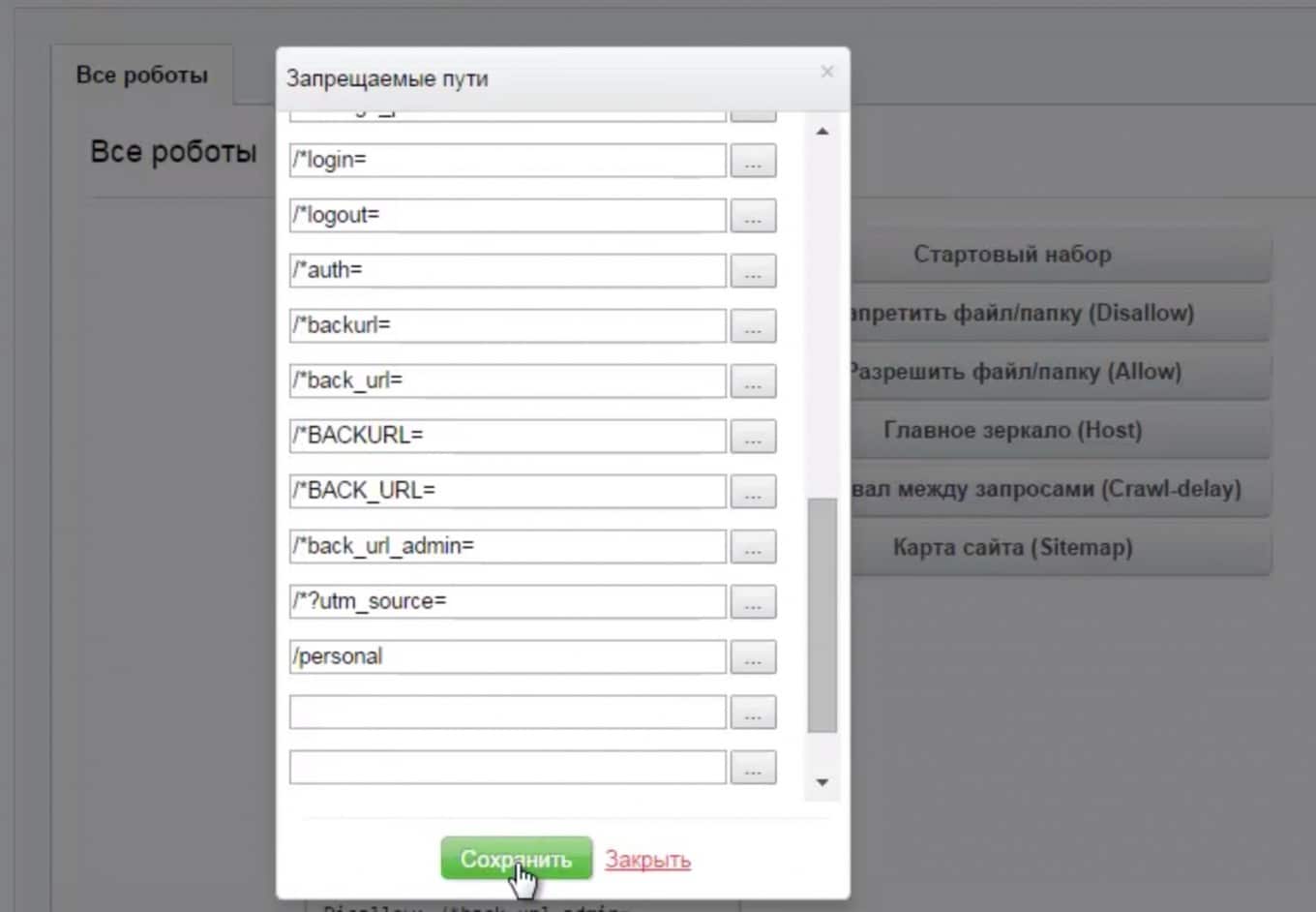
Осталось сохранить файл – все готово. Видео-инструкция по созданию файла robots в Битрикс
8.3. Создание файла robots в Джумла
Создайте новый файл:

С типовым набором директив Joomla:
User-agent: Yandex
Disallow: /administrator/
Disallow: /cache/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /modules/
Disallow: /plugins/
Disallow: /tmp/
Disallow: /layouts/
Disallow: /cli/
Disallow: /bin/
Disallow: /logs/
Disallow: /components/
Disallow: /component/
Disallow: /component/tags*
Disallow: /*mailto/
Disallow: /*.pdf
Disallow: /*%
Disallow: /index.php
User-agent: *
Allow: /*.css?*$
Allow: /*.js?*$
Allow: /*.jpg?*$
Allow: /*.png?*$
Disallow: /administrator/
Disallow: /cache/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /modules/
Disallow: /plugins/
Disallow: /tmp/
Disallow: /layouts/
Disallow: /cli/
Disallow: /bin/
Disallow: /logs/
Disallow: /components/
Disallow: /component/
Disallow: /*mailto/
Disallow: /*.pdf
Disallow: /*%
Disallow: /index.php
Sitemap: https://domen.ru/sitemap.xml
Естественно настройки файла robots необходимо адаптировать под особенности и задачи вашего сайта.
9. Примеры файлов robots.txt известных сайтов
Мы собрали 5 примеров настройки robots.txt популярных сайтов в Украине и в мире. Местами можно “подсмотреть” интересные решения. Так или иначе, речь идет о стандарте, который использует и сам Google.
Пример файла robots.txt в Rozetka:
https://rozetka.com.ua/robots.txt

Еще один хороший пример файла robots в Пром.юа:
http://prom.ua/robots.txt

Другие интересные примеры:
Пример файла robots.txt в Hotline:
https://hotline.ua/robots.txt
Пример файла robots.txt в Google:
https://www.google.com/robots.txt
Пример файла robots.txt в Твиттере:
https://twitter.com/robots.txt
Пример файла robots.txt в Facebook:
https://www.facebook.com/robots.txt
10. Важность закрытия ненужных страниц от индексации
Простая математика. Предположим, у вас есть интернет-магазин, у которого 100 категорий, 700-800 товаров, другие страницы, около 1000 страниц.
Если на сайте есть дубли, страницы сгенерированные CMS и тд, реальных страниц может быть и 2000 – 3000.
Робот обращается к серверу, попадает на эти страницы и начинает их обходить. При этом он может не доходить до части нужных страниц в принципе.
Почему нужно закрывать ненужные страницы от индексации?
- ненужные страницы, например дубли могут индексироваться и попадать в индекс и результаты поиска;
- неэффективно расходуется краулинговый бюджет сайта.
Краулинговый бюджет – это определенный объем страниц, который готов просканировать робот по вашему сайту. У каждого сайта свой краулинговый бюджет.
Если сайт небольшой, шансов получить сложности для продвижения – минимум, а вот большим сайтам нужно побеспокоиться.
10.1. Какие страницы нужно закрывать от индексации:
Следующие типы страниц необходимо закрывать от индексации ВСЕГДА:
- дублированный контент (дубли страниц);
- динамические страницы с параметрами;
- страницы, которые на стадии разработки;
- пустые страницы;
- версии страниц для печати;
- пользовательские формы (формы заказа, страница регистрации, страница авторизации, корзина и т.д.);
- сравнения товаров;
- личный кабинет;
- технические страницы сайта;
- страницы сортировки;
- списки желаний;
- страницы с персональными данными.
А также страницы, которые необходимо закрывать от индексации, но не как правило (бывают случае, когда эти страницы уместно сотавить в индексе):
- страницы пагинации;
- страницы поиска;
- страницы пользователей.
10.2. Что лучше использовать robots.txt или meta noindex
Для Яндекса файл robots.txt – обязательная директива, для Google – рекомендация. К тому же, робот может обращаться к файлу robots не при каждом обращение к серверу.
По возможности – удалите ненужные страницы. Если это невозможно с технической точки зрения – установите мета-тег
<meta name="robots" content="noindex" />
Если речь идет о дублированном контенте, вы также можете установить тег rel=”canonical” на страницы дубли, с указанием ссылки на основную страницу.
Также вы можете воспользоваться тегом X-ROBOTS
Если данные решения невозможно внедрить с технической точки зрения – используйте директиву Disallow в файле роботс.
Так все же все таки разница?
Директива Disallow в файле роботс. Файл robots.txt указывает поисковым системам не сканировать определенный URL на веб-сайте, другими словами НЕ смотреть, но если они знают об этой странице – она будет проиндексирована. Т.е. знают? К примеру вы прописали в роботсе запрет на индексацию конкретного урла, НО робот:
- мог сканировать ее ранее, а теперь вы сказали не сканировать;
- на этот урл могут вести ссылки с вашего сайта или других сайтов.
Другими словами – робот знает знает. Что бывает в таком случае, когда робот знает о странице, а вы говорите сканировать нельзя:
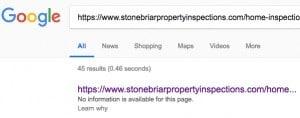
Поэтому иногда гугл может оставлять страницы в индексе даже после запрета ее сканирования через роботс.
Мета тег ноуиндекс. Мета-тег <meta name="robots" content="noindex" /> означает для робота, который обращается к этой странице “Не индексируй меня”, т.е. робот может сканировать этот адрес, но не может его проиндексировать.
10.3. Для чего robots.txt НЕ нужно использовать
В каких случаях и какие страницы закрывать через роботс не правильно:
- Для запрета страниц страниц пагинации
Как правильно: используйте rel=canonical. - Для запрета страниц сортировки
Как правильно: установите мета-тег robots noindex или используйте x-robots - Для запрета страниц-дублей (дублированного контента)
Как правильно: удалите дубли (404 ответ), установите мета-тег robots noindex или используйте x-robots - Для удаления страниц из индекса
Как правильно: установите мета-тег robots noindex или используйте x-robots - Для запрета страниц, которые вы не хотите индексировать
Как правильно: установите мета-тег robots noindex или используйте x-robots
11. Заключение
Разобрались зачем нужен файл роботс? Подытожим.
Файл роботс – инструмент управления индексацией сайта для вебмастера, SEO-специалиста и владельца сайта.
Проверка и настройка данного системного файла всегда в первых рядах чек-листа любого сеошника или агентства.
Неиспользование данного инструмента может создавать серьезные сложности для продвижения проекта, а также сервера, на котором расположен сайт.
Поэтому, убедитесь, что у вас на сайте правильный роботс тхт. Не уверены – отправляйте сам к нам на аудит.

 (3 оценок, среднее: 5,00 из 5)
(3 оценок, среднее: 5,00 из 5)






