

Другие статьи





Что такое веб-архив и его основные функции
Web archive — это онлайн-сервис, обеспечивающий сохранение копий веб-страниц для доступа к ним в будущем. Они позволяют создавать снимки сайтов, которые отображают их вид и контент на определенный момент времени. Это особенно важно, ведь информация на сайтах может меняться или удаляться.
Прежде чем рассказать о webarchive, стоит разобраться с целью сервиса. Основная цель веб-архивов заключается в обеспечении доступа к цифровому контенту, который больше недоступен в обычном режиме. Эти сервисы хранят не только текстовую информацию, но и изображения, видео и структуру страниц. Это делает их полезными как для обычных пользователей, так и для исследователей, юристов или журналистов, которым нужен доступ к историческим версиям сайтов.
Важность сохранения истории веб-сайтов
Сохранение истории веб-сайтов является важным элементом в развитии информационного общества. Веб-контент меняется быстро: статьи обновляются, страницы удаляются, а сайты могут перестать существовать. Благодаря веб-архивам эта информация не исчезает бесследно, а остается доступной для анализа и исследований.
Сохраненные копии сайтов помогают не только избежать потери данных, но и сохранять культурное и техническое наследие. Это важно для создания исторических записей, которые отражают развитие веб-технологий, контента и дизайна. Веб-архивы также помогают в разрешении правовых споров, научных исследованиях и восстановлении утраченных данных.
Причины, почему пользователям нужно пересмотреть старые версии сайтов
Зачем вам знать как посмотреть Webarchives? Иногда возникает потребность вернуться к предыдущим версиям веб-сайтов. Это может быть связано как с профессиональными, так и с личными потребностями. Старые версии часто содержат уникальные данные, которые были изменены, удалены или утеряны.
Основные причины пересмотра старых версий сайтов:
1. Проверка изменений в контенте
Например, для анализа, как обновлялся сайт или какие данные были удалены.
2. Доступ к утраченной информации
Если сайт больше не работает, архивы позволяют восстановить нужные данные.
3. Сохранение доказательств
Иногда необходимо подтвердить, что определенная информация была размещена на сайте, например, по юридическим делам.
4. Научные или образовательные исследования
Например, изучение истории изменений в веб-дизайне или контенте.
Эти причины показывают, насколько ценны веб-архивы как инструменты сохранения информации.
Примеры использования веб-архивов в различных сферах
Web archive используются во многих отраслях, поскольку они хранят не только копии сайтов, но и ценную информацию, которую можно использовать в исследованиях, расследованиях или других профессиональных целях.
Примеры их использования:
- Журналистика
Архивы позволяют восстанавливать удаленные статьи или страницы, что может быть критически важным для расследований.
- Образование
Студенты и преподаватели могут исследовать изменения в веб-контенте или использовать архивные материалы в своих проектах.
- Юридическая практика
Сохраненные страницы могут служить доказательствами в судебных делах, например, для защиты авторских прав или решения спорных вопросов.
- История и архивоведение
Веб-архивы помогают хранить цифровую историю для анализа будущими поколениями.
Эти примеры показывают, что веб-архивы являются не только источником данных, но и инструментом для обеспечения прозрачности и сохранения истории.
Основные сервисы веб-архива
Среди множества веб-архивов выделяются несколько самых популярных и эффективных. Они различаются функционалом, возможностями сохранения страниц и способами доступа к архивным данным.
Популярные сервисы веб-архивов:
Один из самых известных архивов, хранящий сайты с 1996 года.
Инструмент для создания моментальных снимков сайтов.
3. Google Cache
Временный архив поисковой системы Google.

4. Perma.cc
Специализированный сервис для создания постоянных ссылок в юридической и академической деятельности.
 5. Memento
5. Memento
Система, позволяющая одновременно искать сохраненные страницы в нескольких архивах.
 Далее рассмотрим основные сервисы подробнее.
Далее рассмотрим основные сервисы подробнее.
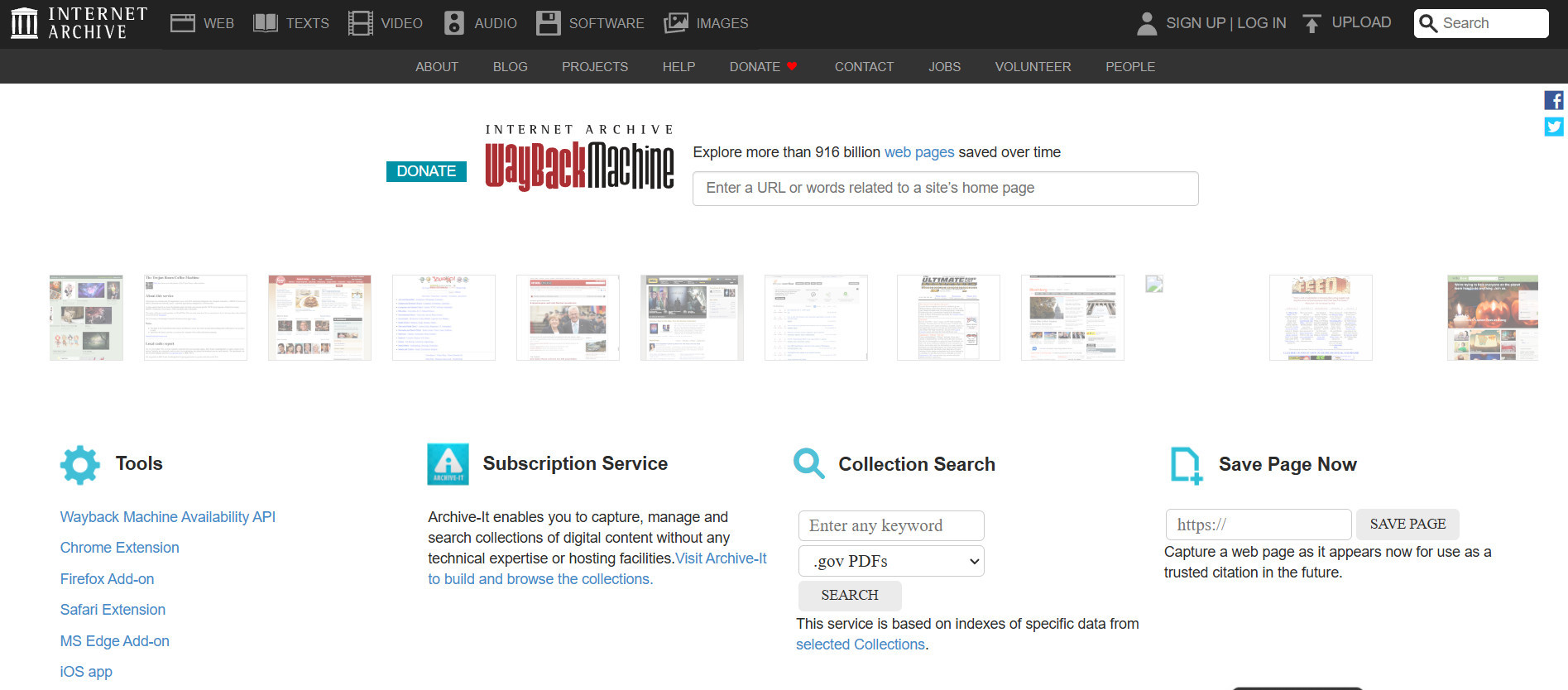
Wayback Machine
Wayback Machine — самый популярный веб-архив в мире. Его база данных содержит миллиарды веб-страниц, начиная с 1996 года. Сервис автоматически собирает информацию о сайтах, позволяя просматривать старые версии страниц за разные даты.
Основные возможности и функции:
- Поиск по URL для просмотра сохраненных страниц.
- Навигация по календарю, который показывает доступные даты архивирования.
- Загрузка копий страниц для офлайн-использования.
- Доступ к различным медиа, сохраненных с сайта (изображения, видео и т.д.).
Wayback Machine не требует создания аккаунта для просмотра данных. Однако зарегистрированные пользователи получают возможность создавать собственные архивы или загружать большие файлы.
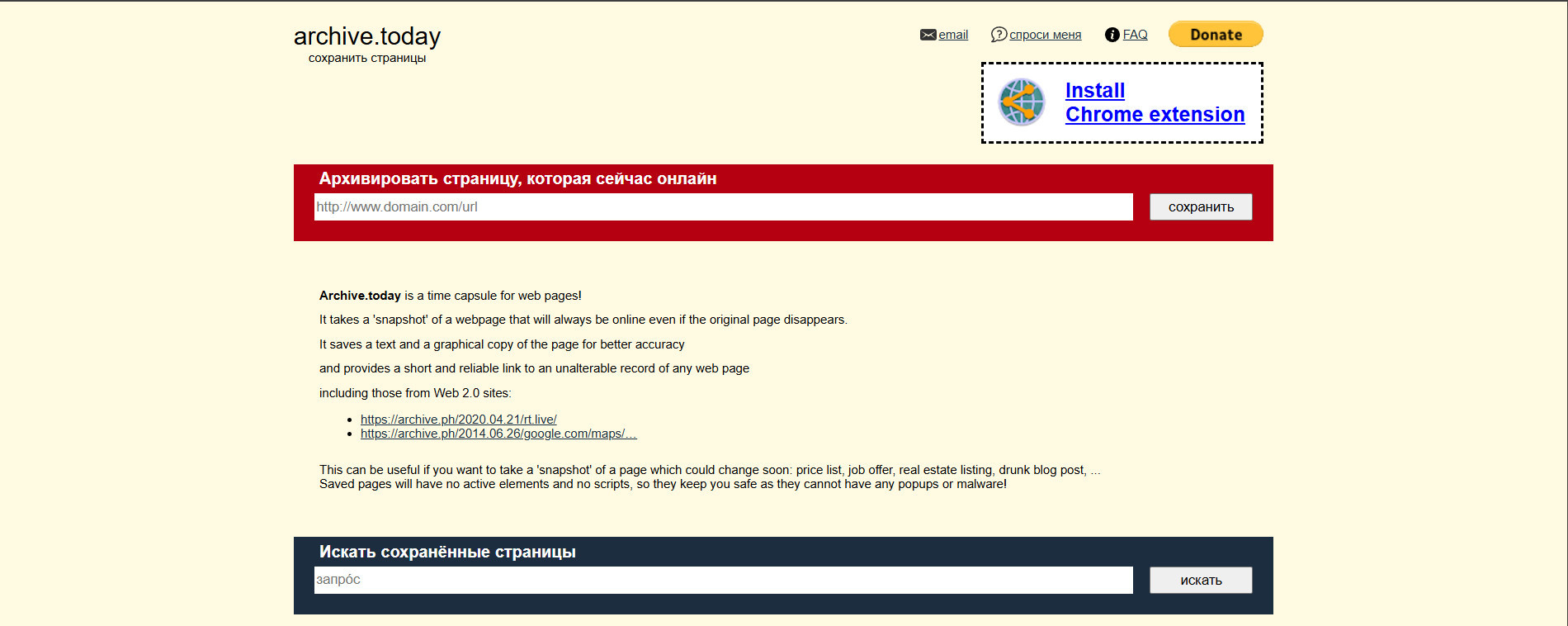
Archive.today
Archive.today — это веб-архив, который создает статические копии сайтов по запросу пользователя. Он известен своей скоростью и возможностью архивировать страницы, даже если они заблокированы для других архивов.
Archive.today сохраняет только одну версию страницы, тогда как Wayback Machine позволяет просматривать несколько вариантов на разные даты. Archive.today подходит для мгновенного архивирования конкретных страниц, тогда как Wayback Machine больше ориентирован на автоматическое сохранение сайтов.
Archive.today полностью бесплатный и не требует регистрации. Это делает его удобным и быстрым в использовании для любого пользователя.
Другие популярные сервисы
Кроме Wayback Machine и Archive.today, существуют другие сервисы, которые также помогают сохранять копии веб-контента:
- Вебархив Google Cache
Временное сохранение страниц, которые были проиндексированы Google.
- Веб архив Perma.cc
Идеальный инструмент для научных и юридических целей, создающий неизменные ссылки.
- Вебархив Мементо
Уникальный сервис, который объединяет поиск страниц в разных архивах, что позволяет получить более комплексную информацию.
Эти сервисы расширяют возможности сохранения и доступа к архивному контенту.
Как пользоваться Wayback Machine
Wayback Machine является одним из самых удобных инструментов для просмотра истории веб-страниц. Благодаря простому интерфейсу пользователь может найти и исследовать старые версии сайтов в несколько шагов.
Поиск сохраненных версий сайта
Поиск сохраненных страниц в Wayback Machine начинается с ввода URL-адреса в поле поиска. Сервис автоматически отобразит календарь, в котором обозначены даты, когда страница была сохранена.
Для этого нужно:
- Открыть сайт Wayback Machine.
- Ввести URL в поисковое поле.
- Выбрать нужную дату в календаре.
Пользователи могут выбирать между разными снимками, сохраненными в разные даты, что позволяет сравнивать изменения на сайте.
Навигация по календарю архива
Календарь в Wayback Machine является основным инструментом навигации. На нем отображены доступные даты архивирования в виде цветных точек или подсвеченных дней.
Навигация включает следующие этапы:
- Выбор года на шкале времени.
- Клик на месяц и день в календаре.
- Просмотр списка сохраненных копий за выбранный день.
Этот подход позволяет найти даже самые старые версии сайта, которые были сохранены годами ранее.
Просмотр сохраненных страниц
Просмотр архива позволяет полностью взаимодействовать с сохраненной страницей. Она отображает не только текст и изображения, но и другие интерактивные элементы. Это полезно для анализа сайта, особенно если оригинал больше не доступен.
Интерфейс просмотра интуитивно понятен и включает следующие функции:
- Выбор другой даты архива прямо с просмотренной страницы.
- Ссылки на сохраненные медиафайлы и документы.
- Загрузка копий для офлайн-анализа.
Wayback Machine позволяет сохранять снимки страниц, чтобы обеспечить доступ к ним независимо от архива. Это может быть полезно для создания собственных баз данных или для исследования.
Чтобы сохранить страницу:
- Нажмите на кнопку «Save Page Now» (Сохранить страницу сейчас).
- Система создаст новую копию и предоставит вам прямую ссылку на нее.
- Используйте загруженную страницу для анализа или в качестве доказательства.
Использование других веб-архивов
Кроме Wayback Machine, существуют и другие сервисы, которые могут быть удобными для просмотра сохраненных страниц. Например, Google Cache позволяет быстро найти копию страницы, которая была проиндексирована Google, но сейчас недоступна.
Архивы, такие как Perma.cc, полезны для создания постоянных ссылок. Они особенно актуальны для академических работ, ведь позволяют цитировать страницы, которые будут оставаться доступными в неизменном виде.
Как пользоваться Archive.today
Archive.today — это быстрый и точный инструмент для создания моментальных снимков веб-страниц. Его простота делает его популярным среди пользователей, которые хотят заархивировать информацию вручную.
Как сохранять страницы
Процесс архивирования страницы в Archive.today очень прост:
- Посетите сайт Archive.today.
- Вставьте URL страницы в поле для архивирования.
- Нажмите «Save» (Сохранить).
Сервис автоматически создаст статическую копию страницы и предоставит прямую ссылку на нее. Перед сохранением страницы можно просмотреть информацию о том, сохранялась ли уже эта страница ранее. Это удобно для проверки дублирования.
Особенности и ограничения
В отличие от Wayback Machine, Archive.today создает только одну версию страницы для каждого архивирования. Это ограничивает возможность просмотра истории изменений, но обеспечивает более точное сохранение.
Преимущества Archive.today:
- Возможность сохранять страницы, недоступные для других архивов.
- Предоставление коротких ссылок на сохраненный контент.
Среди ограничений — невозможность автоматического архивирования сайтов и ограниченный доступ к интерактивному контенту.
Специализированные архивы
Кроме общих архивов, существуют сервисы, созданные для работы с конкретными типами контента, например, видео или изображениями. Они помогают хранить цифровые данные в уникальном формате.
Примеры специализированных архивов:
- YouTube DataViewer: Для архивирования и анализа видео.
- Flickr Commons: Для сохранения фотографий и медиафайлов.
- Internet Archive Video Archive: Специализируется на сохранении видеоконтента.
Как находить контент по конкретным датам
Чтобы найти контент по конкретным датам в архивах, можно использовать различные методы и инструменты, которые облегчают доступ к нужной информации.
Фильтрация по дате
Во многих архивах, таких как Internet Archive или Getty Images, доступны специальные фильтры, позволяющие ограничить поиск определенным временным периодом. Это особенно полезно, если вам нужно найти материалы, соответствующие конкретному году.
Календарь поиска
Сервисы, такие как Wayback Machine, предлагают интерактивный календарь, который позволяет выбирать контент, сохраненный в конкретный день. Например, вы можете просмотреть веб-страницы в том виде, в котором они существовали в определенный момент в прошлом.
Ключевые слова и метаданные
Еще один эффективный способ сузить поиск — использовать ключевые слова или метаданные. Ввод информации, например год, дата или специфический термин (например, «1945 photography»), позволяет архиву быстро выдать результаты, соответствующие вашим запросам.
Использование фильтров и календаря
Фильтры и календари поиска являются самыми удобными инструментами для нахождения нужного контента. Они позволяют найти нужный контент:
- Выбирать формат файлов (например, изображения, текст или аудио).
- Ограничивать результаты по времени.
- Определять условия лицензирования (например, Creative Commons).
- Настраивать поиск по дополнительным категориям, таким как цвет, стиль или тип документа.
Благодаря таким инструментам, вы сможете быстро и точно найти нужный архивный материал, даже если ваш запрос касается определенного периода или даты.
Как запретить добавление сайта в веб-архив
Некоторые владельцы сайтов не хотят, чтобы их контент хранился в архивах. Для этого есть несколько методов, которые помогают ограничить доступ веб-архивов к вашему сайту.
Один из самых распространенных способов — настроить файл robots.txt. Добавьте в этот файл следующую строку:
makefile
Копировать код
User-agent: ia_archiver
Disallow: /
Это запретит доступ архиватору Wayback Machine.
Как восстановить сайт из веб-архива?
Восстановление сайта с помощью веб-архива возможно, если сохранены его важные страницы. Используя Wayback Machine, можно скачать необходимые элементы страниц и воссоздать их локально.
Для этого можно сделать это:
- Откройте нужную страницу в архиве.
- Скопируйте HTML-код и загрузите медиафайлы.
- Создайте локальную копию страницы или интегрируйте ее на новый сайт.
Висновки
Веб-архивы — это мощный инструмент для сохранения истории интернета. Они позволяют получить доступ к старым версиям сайтов, восстанавливать информацию и анализировать изменения. Используя такие сервисы, как Wayback Machine и Archive.today, вы можете сохранить важные данные для будущего использования.
Другие статьи



